I was never able to get into Game of Thrones. I thought the books were slow reading and that the TV show was kind of boring. But, I will admit that parts of the narrative do absolutely fascinate me – I’m interested in the white walkers and the history, culture, and geography of the world. Basically, anything that isn’t the actual the story is pretty cool.
But, Game of Thrones is extremely character rich, and those characters are very busy vying for power. Murders and betrayals are rampant, and apparently, you shouldn’t get too attached to a character because he or she may very well be killed off. Last year, a few students at Olin College created a Bayesian survival model (for the books) to estimate a character’s chances of surviving until the end of the series. View it here.
People die of all sorts of causes, but the most emotionally (and narratively) significant ones are the betrayals. So, let’s extend the analysis a bit. What are the characteristics of a character who is betrayed?
The Data
I obtained the data from two places. First, I used the dataset Ben Kahle and Erin Pierce, the Olin College students from above, collected which has information on every named character in the first five books of the series. Second, I used data collected by Sara McGuire, Joanna Lu, and Eugene Woo about every betrayal in the TV show. The first dataset can be found here, and the second can be found here.
We have a fairly apparent problem. There are tons of characters who haven’t committed betrayals, but there are probably characters in the book who are not in the Game of Thrones show (which our betrayals are from). So, I went through and found the major and minor characters from seasons 1 through 5 (but not mentioned characters) and removed any characters not also present in the TV show from the dataset.
I am assuming that the show and books are similar enough for seasons 1-5, but let me know if there are any major differences. Given the amount of data, I doubt one or two incorrect observations would greatly affect the model, but it’s poor statistical practice to not acknowledge the possibility of bad data.
The Logistic Regression Model
Logistic regression is a type of generalized linear model. We’ll be using binary logistic regression which maps a set of explanatory variables to a binary response, usually 0 and 1. As opposed to normal linear regression where the value of the predictors should map to the expected value of the response, logistic regression maps the values of the predictors to the odds (or probability) of the response being either 0 or 1.
So practically, what does this mean? Say we have a set of explanatory variables (the character’s house, gender, nobility etc). Then, the value of each of these should affect the odds (probability) of that character being betrayed (a response variable value of 1) or not (response variable value of 0).
Mathematically, this looks like:
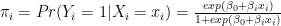
This is alternatively formulated in terms of log-odds:

So, onto some analysis! We’re interested in figuring out the characteristics of characters who get betrayed. The explanatory variables we have to work with are indications of house loyalty, status as a member of the nobility or smallfolk, and the character’s gender.

In the logistic regression model, the coefficients for predictors are the log-odds or how a unit change in the variable changes the log-odds of the response. For nobility, smallfolk was the baseline, and for gender, female was the baseline. In terms of model diagnostics, we find that our model fits better than the null model; this should give us some confidence, along with the significance of our predictors, that we’re on to something.
So, exponentiating back shows us that nobles are 5.5 times as likely to be betrayed as smallfolk are (which makes sense since betrayals are oftentimes about power or loyalty). Very interestingly, though, males are about 40% as likely as women to be betrayed. We can directly calculate the probability that some random character with certain characteristics is betrayed then:
Probability of a Random Character Being Betrayed

I’m glad I’m not a noblewoman! If you happened to be a recurring noblewoman in the show/books, you have almost a 40% chance of being betrayed by virtue of existing! On the other side of that coin though, smallfolk men are very rarely betrayed. This is probably an artifact of Martin’s writing style. It may just not be as interesting (or worthwhile) to betray smallfolk.
In terms of House affiliation (not necessarily being a member of the House), I tried quite a few models to see if certain Houses were more likely to be betrayed, but none of them were significant. At this point, you might be thinking to yourself, “what about the Starks????” Well, when you read the books or watch the show, it follows the main characters much more closely. While reading or watching, you may inadvertently ignore all of the characters affiliated with the Starks (or Lannisters or whomever) who aren’t betrayed. This is an example of improper thinking: just because the betrayed get more screen minutes doesn’t mean that they influence the final model more.
Stochastic Processes
This is all well and good and could be useful for determining if you should get attached to new characters, but it doesn’t really tell us much about the characters we’ve come to know and love. We know that Daenerys and Cersei have been betrayed before, so logistic regression doesn’t really tell us anything new. So, what if we could figure out who was “due” for a betrayal?
The word “stochastic” sounds scary, but it really just refers to a system with inherent randomness. Remember Markov chains? Those are stochastic! So a stochastic process is just a collection of random variables indexed by time (discrete or continuous).
Luckily, the show provides us with very nice, discrete time-like units: episodes. So, we’ll be using a Bernoulli process to calculate the inter-betrayal time for some of our favorite characters. The Bernoulli process is a sequence of random Bernoulli variables whose inter-arrival times (time until next event) are governed by a geometric distribution. If that doesn’t make immediate sense to you, don’t worry. This is equivalent to saying that, in each episode, there is a probability that some character is betrayed. And, we can compute a probability distribution for the arrival time of the next betrayal. Sound good? (There are some assumptions that stochastic processes make – I believe the methodology is applicable, but if you’re interested in my arguments why, let me know).
Daenerys Targaryen
Daenerys (along with Tyrion Lannister) is the most betrayed person in the Game of Thrones universe. She’s been betrayed in 6 separate events. The average person isn’t betrayed at all, but if they are, it’s usually only once or twice.
We use the maximum likelihood estimator (which is a point estimator) to find out the probability that Daenerys is betrayed in a random episode. This just ends up being the number of times she is betrayed divided by the number of episodes, or 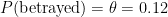
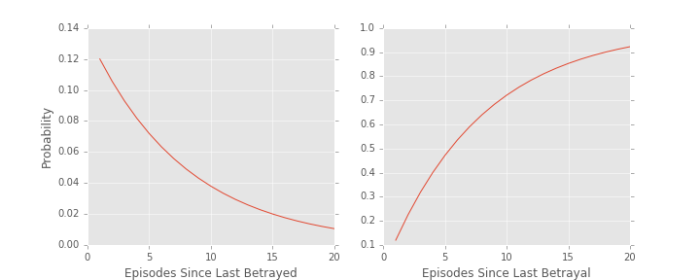
On the left is the probability mass function relating number of episodes since last betrayal to probability that, in some episode, she’s betrayed. The right shows the cumulative distribution function. Thus, there is an approximately 50% chance that Daenerys will be betrayed within 5 episodes of her last betrayal. For fans of the Queen of Dragons, she was last betrayed in Season 5, Episode 9. So, be careful in season 6.
We could use Bayesian statistics to come up with a distribution for 

Tyrion Lannister
Tyrion is the male Daenerys in that he has also been betrayed 6 times. But, according to the data, he was last betrayed in Season 4, Episode 8. So, from our calculations above, Tyrion is statistically ripe for a betrayal.
Others
This table shows the probability that a (living) character who has been betrayed more than once is betrayed within 10 episodes of their last betrayal.

Conclusion and A Note On Statistics
So, what have we learned? There are some underlying patterns to who gets betrayed in Game of Thrones and how frequently we should expect that to happen. These models extend farther than Game of Thrones though. Logistic regression and stochastic processes can be extremely useful for modeling every day events as well. I hope, at least, this was an interesting read.
This entire post has been a study of randomness. But, while we’ve been treating Game of Thrones as random, the plot is not randomly determined. It is determined by what the writers think will make a good story. So, just because a model says someone is likely to be betrayed doesn’t mean that they will be or that they won’t be. We’ve just been using data from the books to see what, under one interpretation, is likely to happen. And I think that’s something very important for people to understand about the analysis of data. These things aren’t deterministic. They’re models that can potentially describe the way things work, not guarantors of the future.

One thought on “Who Gets Betrayed in Game of Thrones?”